Fuzzy Logic - If Only Computers Understood Us
Computers have definitely taken over every aspect of our lives. They are certainly good at one thing: precision. Computers are built on boolean logic meaning that everything is represented as true or false, bit on or bit off. However, this is not ideal when we are working with data. The data that we are interested in is human and we are simply trying to use computers as a means of understanding this human data. But there is one big problem that data scientists seem to encounter time and time again. Data curated by humans is messy. I faced this when I was trying to merge two datasets regarding Miami-Dade County Public Schools. Is “Coral Gables High School” the same as “Coral Gables Senior High School”? To me, a human, I say yes. But a computer using a simple string match compares each character to see if they are equal. If one of the characters does not match, the output of the string comparison will be false.

Enter fuzzy logic. Fuzzy logic is what allows google to display the below image when you have a typo!
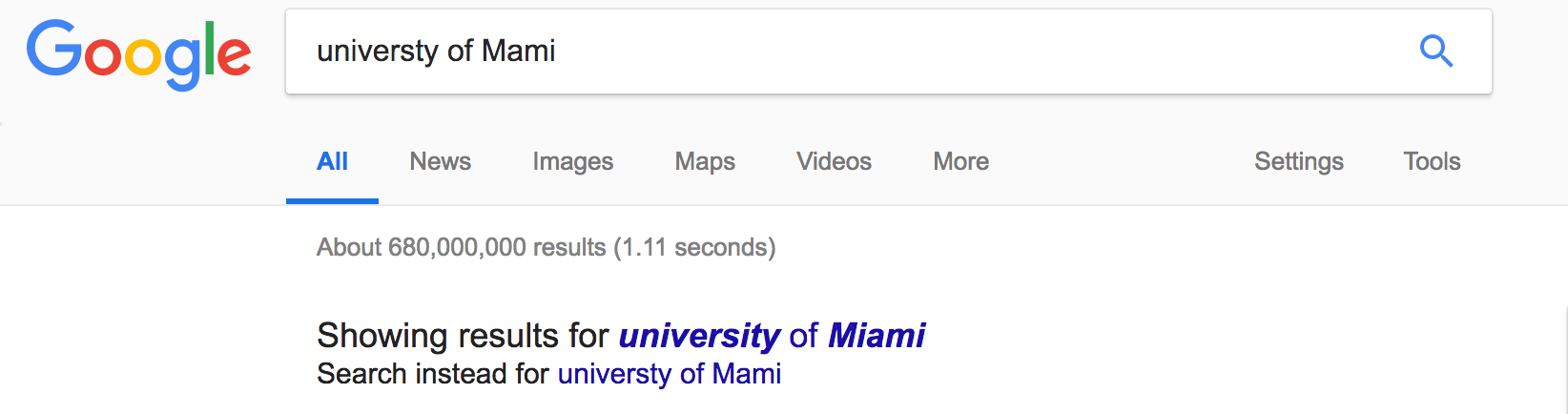
The truth value of a statment with traditional logic is either 0 or 1, that is, true or false. However, with fuzzy logic, the truth value of a statement can occupy a value from 9 to 1. This is very counterintuitive because we think of truth as absolute. However, when you are asked if two images of an apple are the same, you would respond yes or no although there could be minute differences in the images. How can fuzzy logic be used to help with the string match problem?
install.packages("fuzzyjoin");
mergedData <- stringdist_inner_join(percentage_of_free_reduced, Public_Schools, by = c(NAMES = "School"), max_dist = 5)
The above code will allow for mismatch in the string up to a threshold of 5. That means that if two strings are 5 distance units apart, then the program assigns a truth value of 1. Since this is a user-defined parameter, I would try a bunch of values and pick that one that yields the best results qualitatively.